Ajay Kumar
Data Scientist @ AllHeart Web
Technical Data Scientist specializing specializing in the development of Generative AI, Computer Vision, and high-performance Deep Learning systems. I bridge the gap between theoretical research and production-grade engineering by implementing SOTA architectures—including Transformers, YOLO, and U-Net—from first principles using PyTorch.
My professional expertise spans the end-to-end ML lifecycle: from pretraining custom Foundation Models (1.3B+ tokens) and fine-tuning via PEFT (LoRA), to architecting RAG-based domain intelligence and optimizing models for on-device inference (GGUF/Quantization). I have a proven track record of managing big data pipelines handling millions of records and deploying scalable, fault-tolerant AI services via FastAPI and MLOps frameworks.
Core Focus: Transformer Architectures, Self-Supervised Learning (MAE/ViT), On-Device LLM Inference, and Scalable Backend Engineering.

About Me
Name: Ajay Kumar
Education: B.Tech. in Electronics and Communication
University: Himachal Pradesh Technical University
Current Address: Chandigarh, India
Email: kumarajaypaonta@gmail.com
Work Experience
Data Scientist — All Heart Web
Apr 2025 – Present
- Built and optimized a Whois Data chatbot for whoisdatacenter.com by integrating large-scale datasets and automating data pipelines using Python and Shell scripting.
- Developed a FastAPI-based WHOIS data service enabling structured querying and efficient domain intelligence retrieval.
- Worked extensively with SQL, MongoDB, and Elasticsearch for scalable data storage, querying, and analytics.
- Designed and executed big data pipelines handling millions of records with high reliability.
- Applied Selenium and web scraping techniques to extract structured data from diverse web sources.
- Deployed and monitored production workflows on servers, ensuring performance, stability, and fault tolerance.
Data Analyst Intern — Indicraft Vintage Private Limited
May 2024 – Sep 2024
- Performed data cleaning, preprocessing, and exploratory data analysis to support business decision-making.
- Analyzed large datasets to identify trends, patterns, and actionable insights.
- Created dashboards and reports to communicate findings to stakeholders.
- Collaborated with cross-functional teams to improve data-driven workflows.
Tools and Skills I use.
Python
Git
VS Code
Jupyter Notebook
Google Colab
TensorFlow
PyTorch
Machine Learning
Data Science
Deep Learning
NLP
Scikit-learn
Neural Networks
Streamlit
HTML5
CSS3
Hugging Face Spaces
MLOPS
dvc
mlflow
GEN AI
LLMs
RAG
Web Scraping
FAST API
GANs
Transformers
Vision Transformers
Projects
A curated set of projects exploring data science, machine learning, and AI research. From exploratory analysis and classical ML to deep learning and generative models, these projects highlight my journey of learning AI through theory, code, and experimentation.

Built an end-to-end edge AI pipeline to run Large Language Models fully offline on mobile devices, from model conversion to real-time inference in a Flutter app.
Developed a custom pipeline to convert Qwen2 models (.safetensors) into GGUF format for compatibility with llama.cpp, with full control over tensor mapping and tokenizer integration. Models were then quantized to optimize performance for resource-constrained devices.
Integrated llama.cpp into a Flutter-based chat application to enable real-time, on-device inference with no API calls, no internet dependency, and complete privacy.
Apk Link
App Code
Code
LinkedIn
Quantized model
OnDeviceAI
Qwen2 0.5B
llama.cpp
gguf conversion
GGUF
Quantization (Q4)
LLM
Flutter
C++
CPU-only inference
Hugging Face Spaces

Built a neural machine translation system for Akkadian (ancient, low-resource language) to English as part of the Deep Past Challenge (Kaggle).
The project focuses on handling extreme data scarcity, noisy labels, and unknown scripts using modern parameter-efficient fine-tuning techniques.
Code
Kaggle Dataset / Model
Kaggle Notebook
Transformers
PEFT (LoRA)
PyTorch
SacreBLEU
google/byt5-small
Kaggle competition
Akkadian to English
Hugging Face Spaces
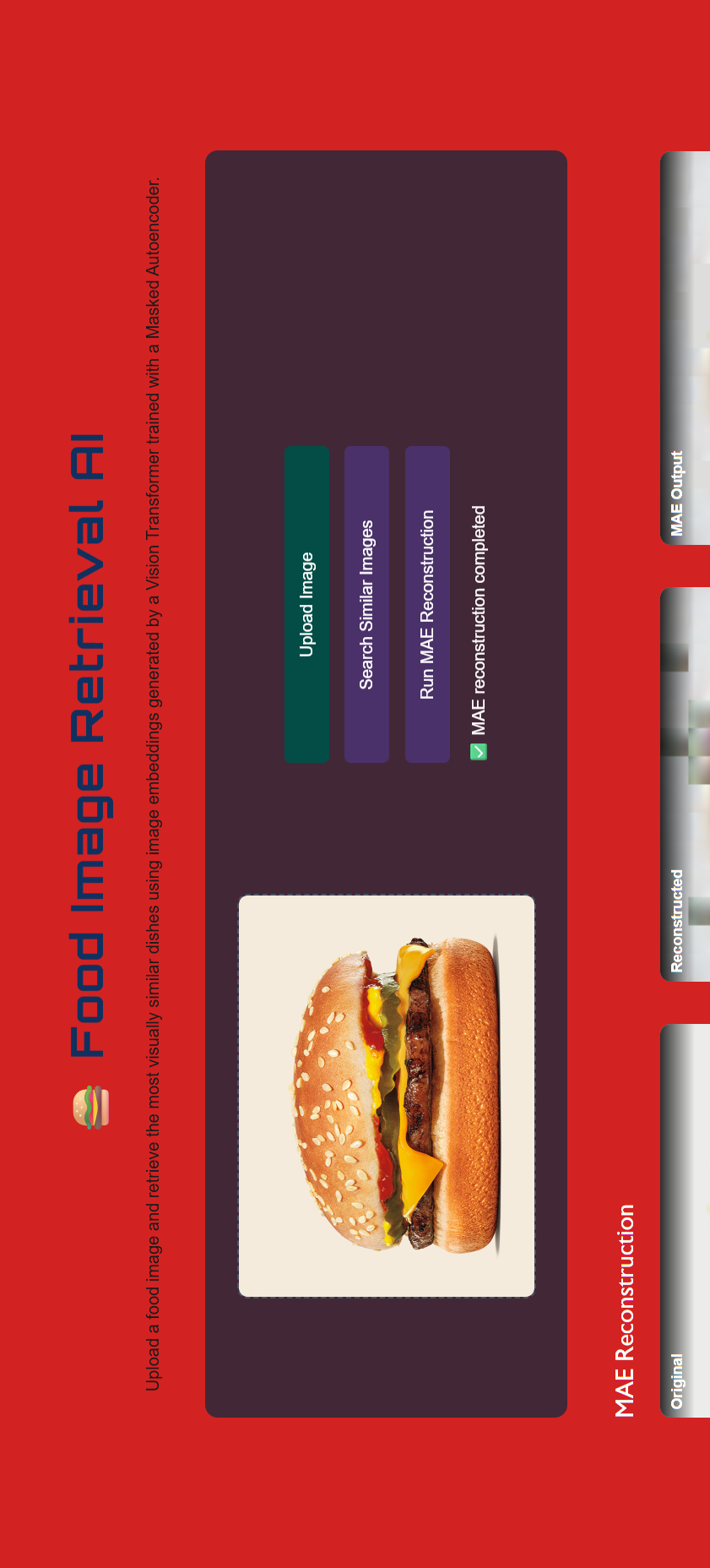
Built a semantic image retrieval system using a Vision Transformer encoder trained with Masked Autoencoder pretraining on the Food-101 dataset.
The encoder generates high-dimensional image embeddings, which are used to retrieve visually similar food images through similarity search.
Additionally, experimented with a Transformer-based caption generation pipeline using cross-attention, highlighting practical challenges in aligning visual features with natural language.
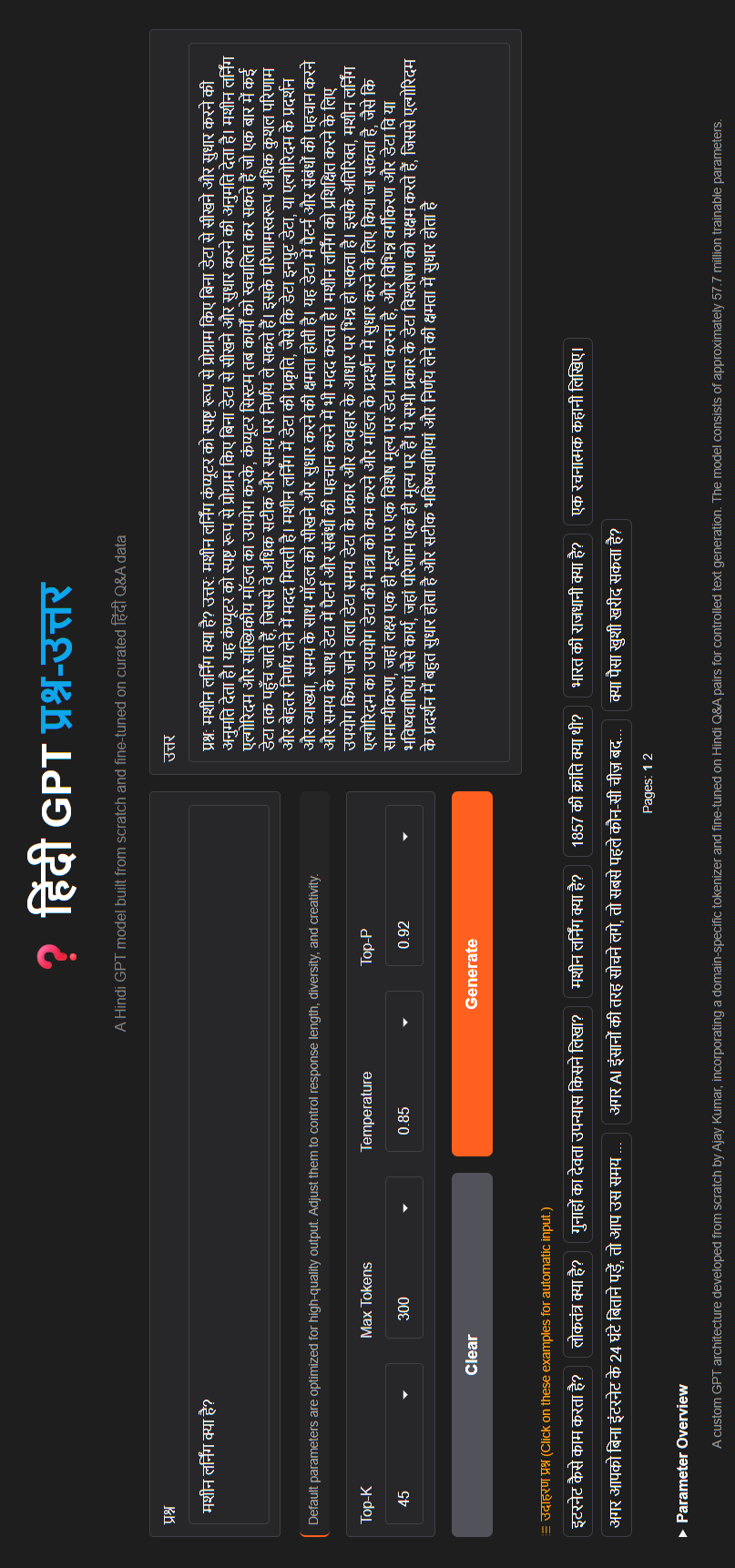
Designed and trained a decoder-only GPT-style language model from scratch in PyTorch, implementing
masked multi-head self-attention with Rotary Positional Embeddings (RoPE), feed-forward networks,
residual connections, normalization, and a stacked decoder architecture from first principles.
The model was pretrained on ~1.35B Hindi tokens using a custom SentencePiece BPE tokenizer
(Hindi-only vocabulary), enabling experimentation with large-scale language modeling,
convergence stability, and efficient training on limited hardware.
Live Link
Pretraining Code
SFT Code
Tokenizer Code
Model files
LinkedIn
Thread
Hindi GPT
GPT Pretraining
SFT
Custome Hindi Tokenizer
Generative AI
Foundation Models
Decoder Only
Transformers
NLP
AttentionIsAllYouNeed
PyTorch
Gradio
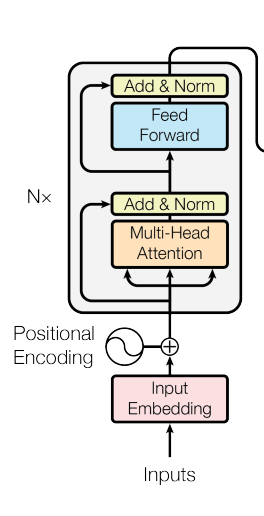
Implementing the Transformer Encoder from scratch using PyTorch — exactly as described in
“Attention is All You Need” and also implements Multi-Head Attention, Positional Encoding,
Feed-Forward networks, Residual+LayerNorm, and an encoder stack from first principles.
The encoder was trained on KP20k (BIO labels) to validate the implementation and to
experiment with attention behavior, head effects and extraction heuristics.
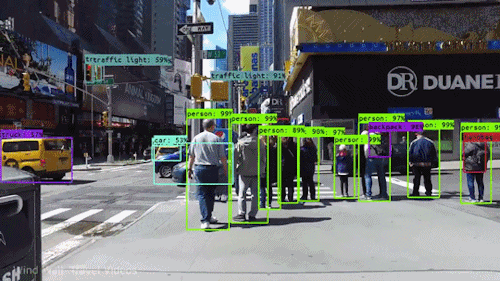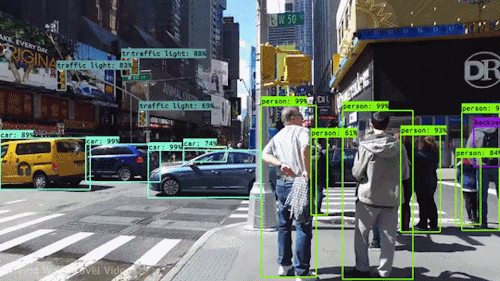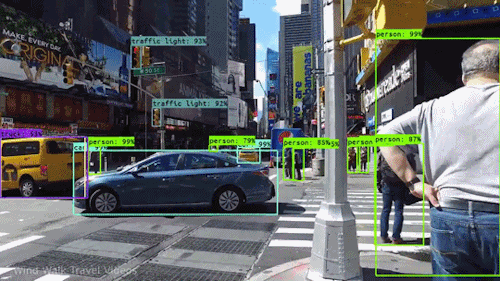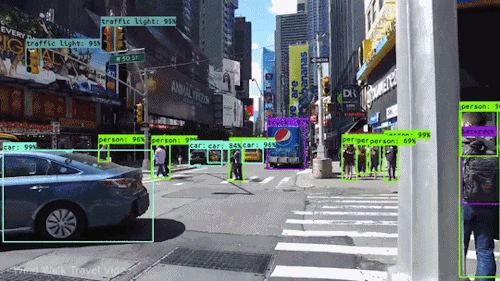
This project is a from-scratch implementation of the YOLOv1 (You Only Look Once) object detection
paper using PyTorch. I implemented the entire pipeline — architecture, loss function,
dataset parsing, and model training — to deeply understand how YOLO works at its core.
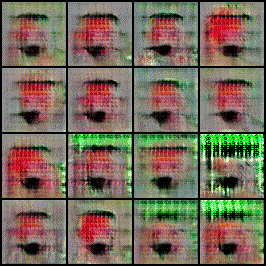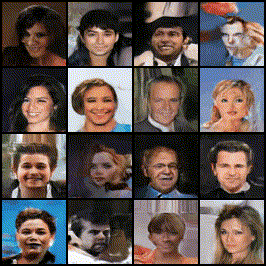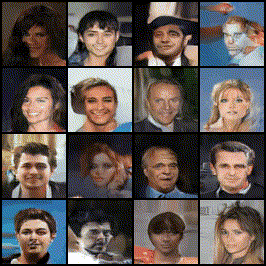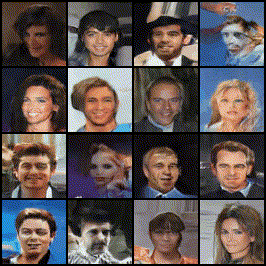
Implemented and trained a DCGAN model to generate realistic human faces using the CelebA dataset.
Built an interactive web interface with Flask, HTML, CSS, and JavaScript that allows users to
generate faces, morph between two faces with a slider, and create batches of 100 synthetic faces.
Deployed the project on Hugging Face Spaces, showcasing end-to-end GAN implementation from research
paper to real-time user interaction.

AI-Powered Stock Market Insights: Building a Chrome Extension with Selenium, FastAPI, and LangChain.
I built a Chrome extension powered by Selenium, FastAPI, and LangChain that works as an
AI-driven stock market chatbot assistant. With a simple natural language query,
it can fetch real-time stock performance, show detailed stats for any stock,
provide sector-wise insights, pull the latest market news, and display interactive
charts — all directly inside the browser.
Medium Blog
Code
LinkedIn
ChromeExtension
AI Agent
StockMarket_Bot
LangChain
Selenium
Scraping
FastAPI
MarketInsights
Automation
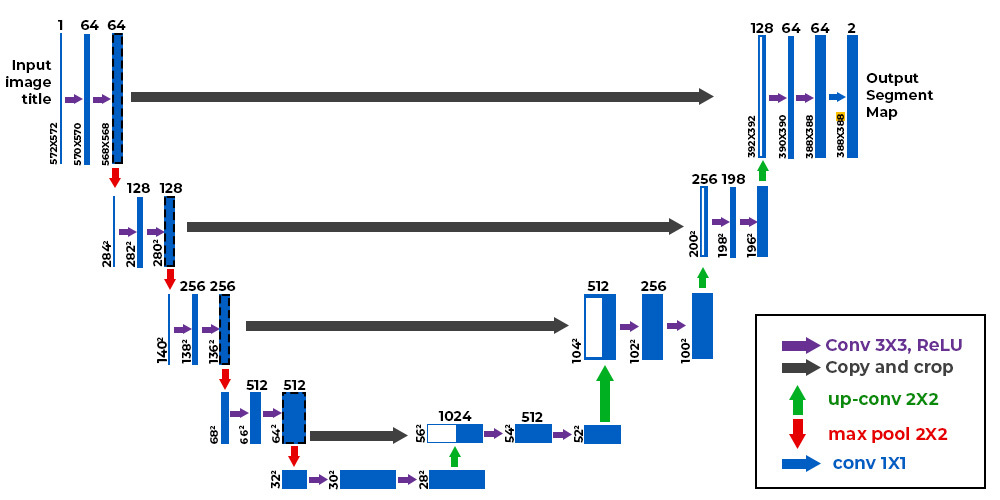
Implementation of U-Net Research Paper using PyTorch for Car Image Segmentation and Mask Generation.
I have implemented the original U-Net research paper using PyTorch and then trained this model
on a car dataset. created the frontend to use this model and generate the mask of the car.
For the frontend, I used Flask, HTML, and CSS. In the app, I can upload an image,
and by clicking a button, it generates the mask and overlay of the original image.
Show more projects

An AI-powered medical assistant leveraging Retrieval-Augmented Generation (RAG)
on WHO data to deliver accurate medical responses. Built with a modular Flask (frontend)
and FastAPI (backend) architecture, integrated with Pinecone for semantic search,
MongoDB for patient data, and containerized with Docker for seamless deployment on
Hugging Face Spaces.
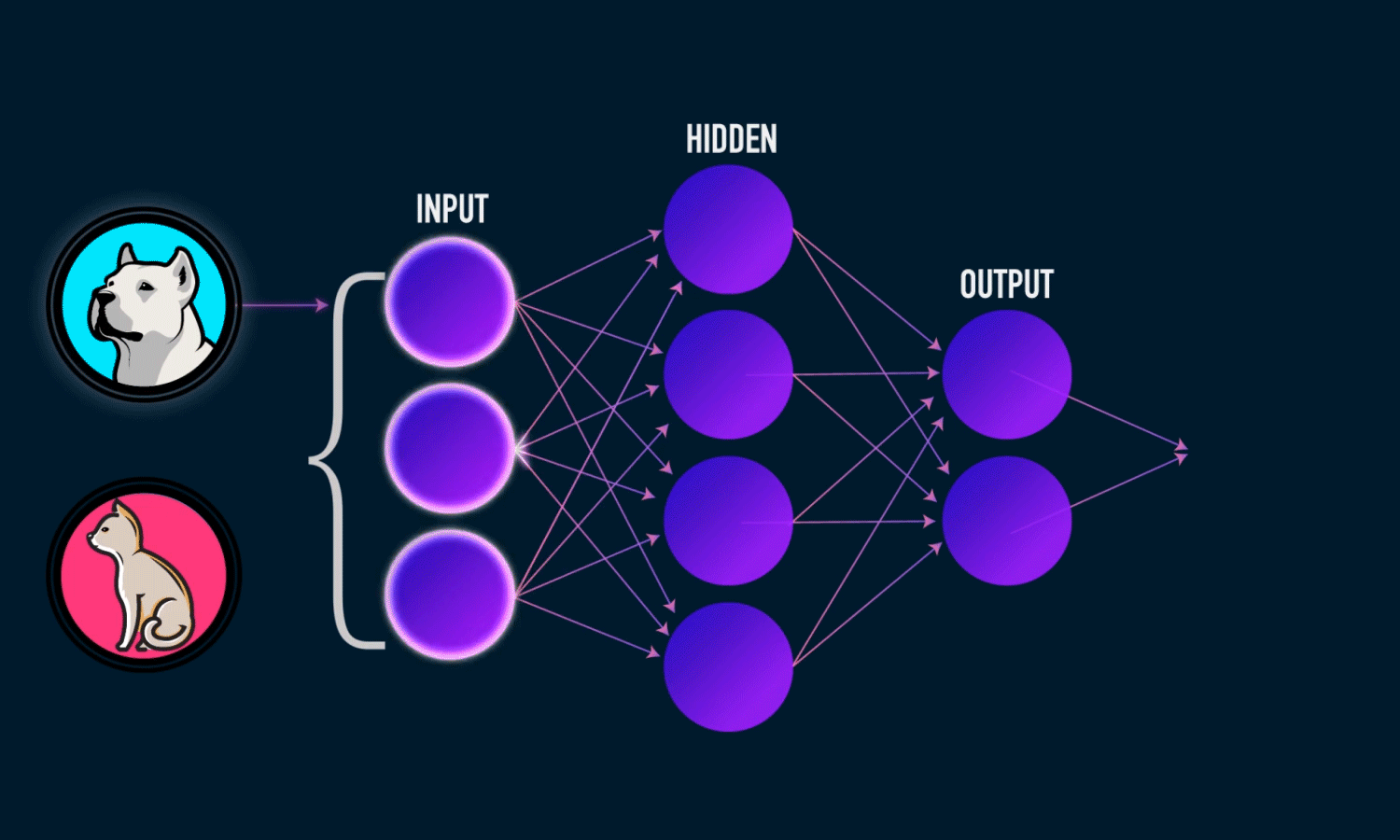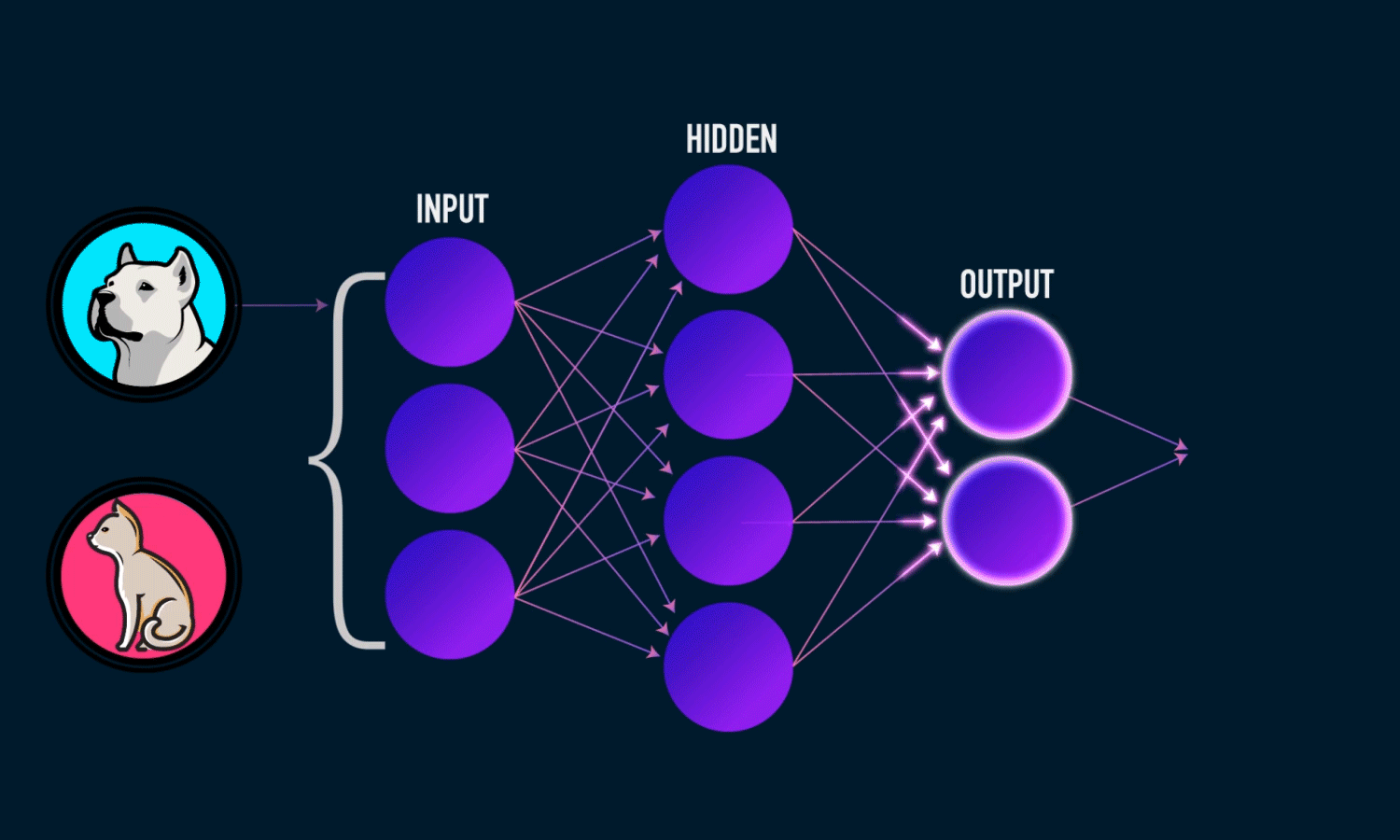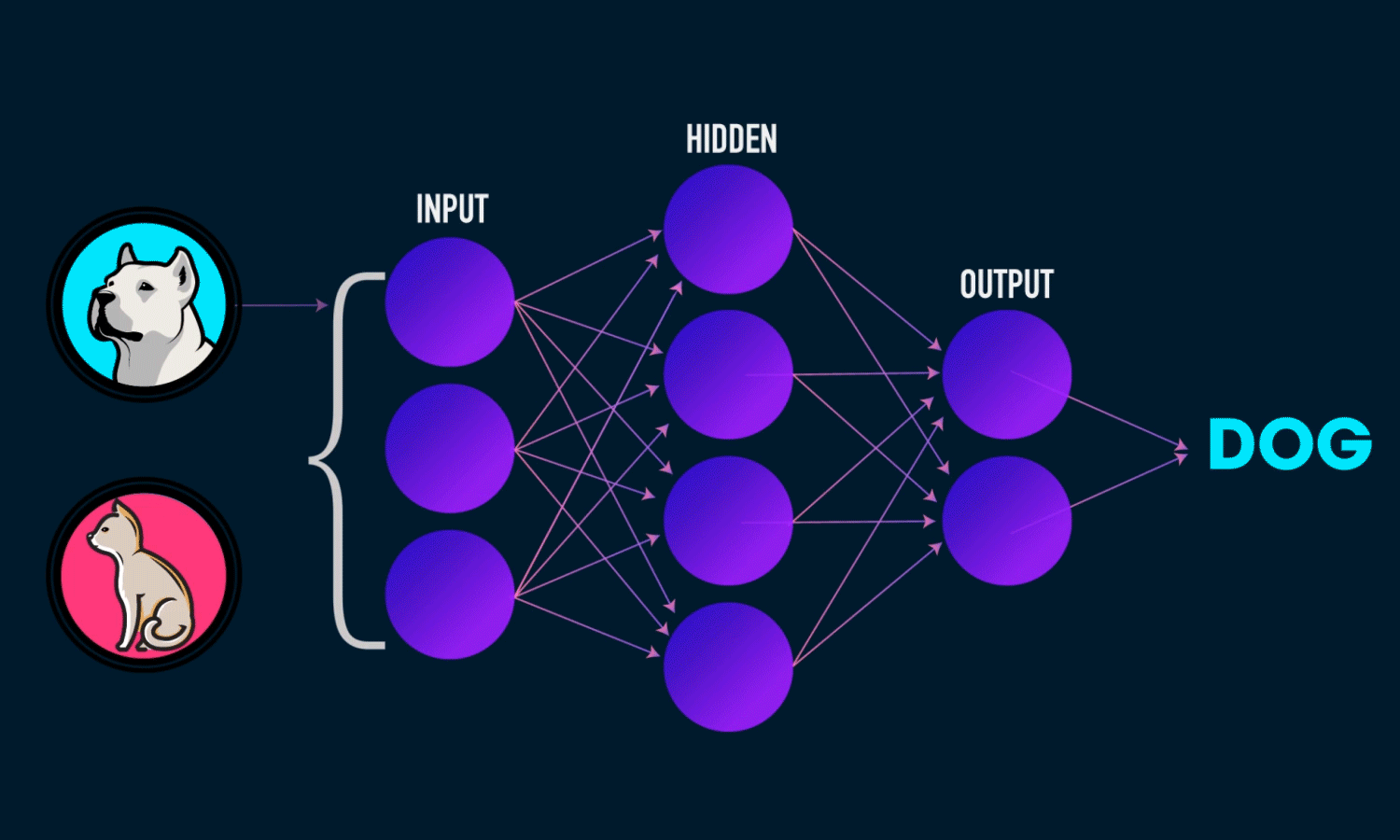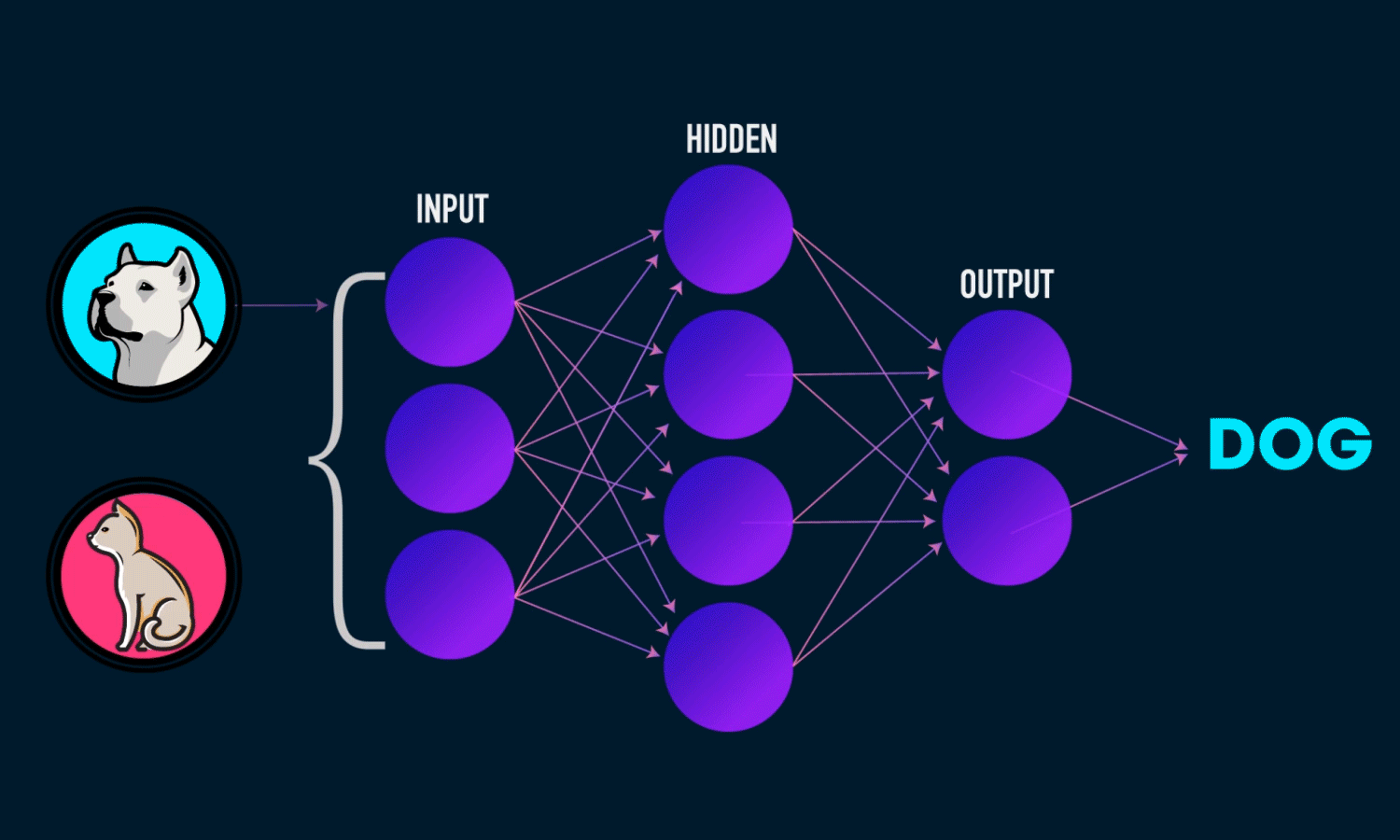
This project is deep learning-based image classification model that distinguishes between
dogs and cats using the ResNet50 architecture. The model leverages transfer learning from
a pretrained ResNet50 network (trained on ImageNet) to achieve high accuracy (95.36%)
with minimal training time.

This project focuses on predicting rainfall using machine learning techniques while
implementing experiment tracking with MLflow and DagsHub. The goal is to build an
accurate model that forecasts rainfall based on meteorological features.

This project focuses on developing a robust Email/SMS Spam Classifier that leverages
machine learning techniques to accurately distinguish between spam (unwanted) and
ham (legitimate) messages.
Live Link
Code
Medium Blog
SpamDetection
NLP
MachineLearning
DataScience
Streamlit
HuggingFaceSpaces

This project predicts customer churn in credit card services using an Artificial
Neural Network (ANN) built with PyTorch. The model was trained on the Credit Card
Customer Churn Prediction dataset from Kaggle, achieving an accuracy of 86%.

In this project, I developed a Book Recommender System using a combination of popularity-based
and collaborative filtering techniques. The system helps users discover books based on their
reading history and interactions with books, and it also highlights the top-rated books.
The model is deployed using a web application built with Streamlit and hosted on Hugging Face.
Live Link
Code
Medium Blog
RecommenderSystem
CollaborativeFiltering
MachineLearning
BookRecommendations
Streamlit
HuggingFaceSpaces

I’ve developed a dynamic web application using Streamlit that offers insightful analysis
of IPL data. This user-friendly app allows enthusiasts to explore the vast IPL dataset
interactively.

I’ve developed a Streamlit web application to visualize and analyze Olympic data.
This app leverages interactive charts and plots to explore various metrics,
such as athlete performance and medal distribution, providing insights into trends and
patterns across different Olympic events. It enhances data understanding through
user-friendly, real-time data exploration tools.
Live Link
Code
Medium Blog
olympicsdataanalysis
DataAnalysis
EDA
Olympics
Streamlit
HuggingFaceSpaces
Blogs
I write about Machine Learning, Deep Learning, NLP, and practical AI concepts with real-world intuition.
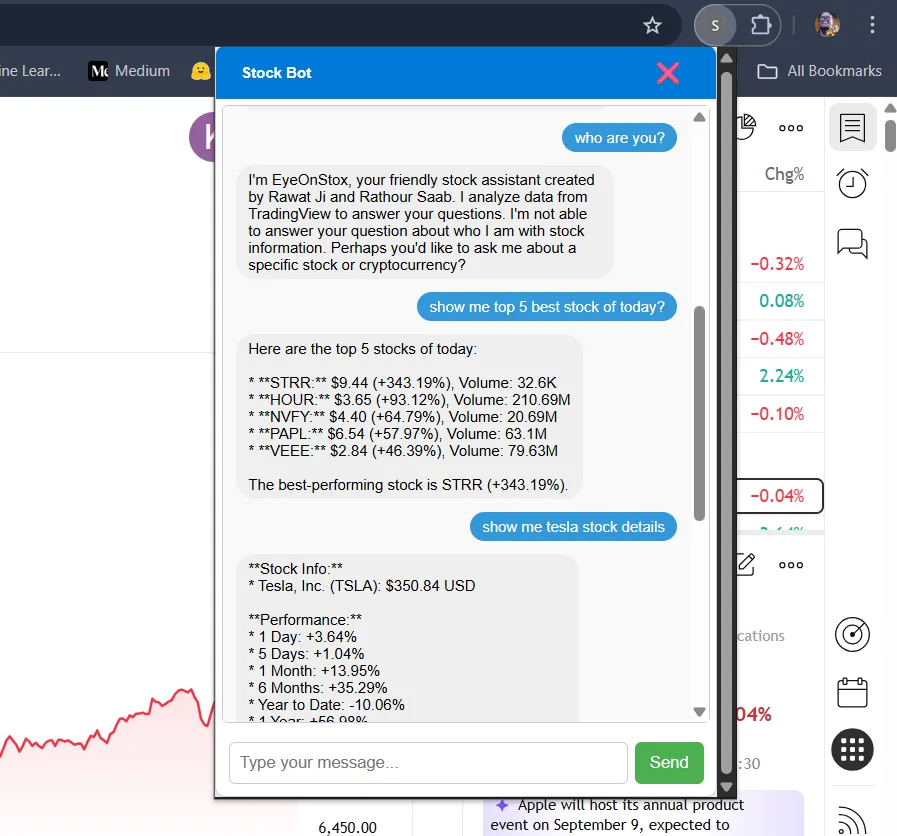
Introduction, The stock market moves fast, and so does the information around it.
Traders often need to check multiple things at once — best and worst performers of the day,
single stock details, the latest news, sector trends, or even a stock chart for a
specific timeframe. Doing this manually can feel repetitive and time-consuming.
That’s where my project comes in.
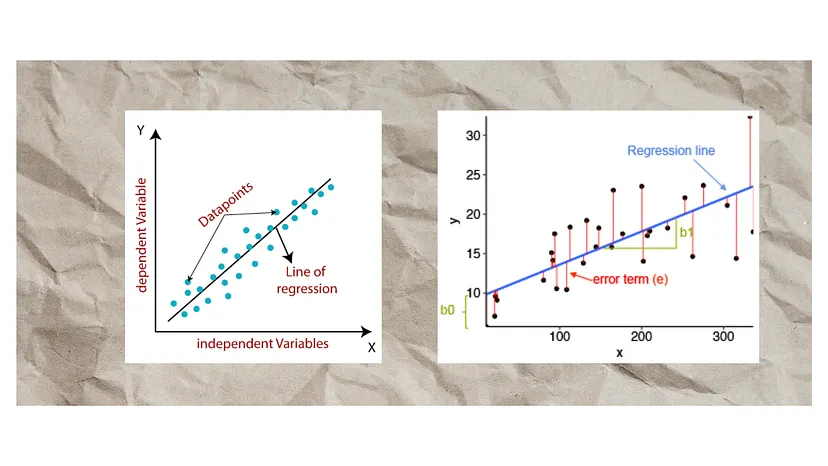
Linear regression is one of the most fundamental algorithms in machine earning, widely
used for predictive modeling. In this guide, we’ll break down the key concepts, interview
questions, and advanced techniques to help you master linear regression from the ground up.
Spam emails and SMS messages have become a significant concern in today’s digital world,
often cluttering inboxes with unwanted content or, worse, phishing attacks.
These messages are an everyday nuisance, clogging our inboxes with unsolicited or
malicious content. Machine learning provides a powerful solution to automatically
classify and filter these messages, improving the user experience.
I implemented a popularity-based recommendation system for the Top 50 Books section.
This system ranks books based on overall popularity, considering factors like highest ratings,
most reviews, and frequent user interactions. It effectively showcases widely-loved and
highly-rated books, making it ideal for users seeking to discover popular titles that have
already gained a strong reputation.
“AI is going to bring a new renaissance for humanity, a new form of enlightenment, if you want, because AI is going to amplify everybody's intelligence.”